Introduction
지난 글에서 내가 어떤 방법을 사용해서 Code Sprint 라운드 2에서 우승을 할 수 있었는지 설명하였다. 이번엔 지난 글에서 못다 한 이야기와 만약 나에게 주어진 시간이 충분했더라면 어떤 식의 접근을 했을지를 논하는 일종의 post-mortem을 이야기해보자.
Bayesian Story
기존 대회에서는 주어진 데이터를 posterior sample이라고 가정하고 문제에 접근하였다. 하지만 이는 제대로 된 베이지안 방식의 접근이 아니다. 조금 더 세련된 베이지안 접근을 취해보자.
- Prior distribution을 만든다.
- Likelihood 계산을 위한 모델을 만든다.
- Bayes' theorem을 사용하여 posterior distribution을 계산한다.
- Posterior distribution에 대한 expected loss를 최소화한다.
Data Generation Model
우리는 예측에 앞서 각 데이터를 생성하는 분포에 관심이 많다. 이는 만약 데이터를 생성하는 분포를 정확하게 알 수 있다면 우리가 원하는 만큼 데이터를 생성하고 이를 활용하여 예측에 사용할 수 있기 때문이다. 데이터가 어떤 방식으로 생성 되었는지에 대한 직관은 데이터를 살펴보면 얻을 수 있는 경우가 많다.
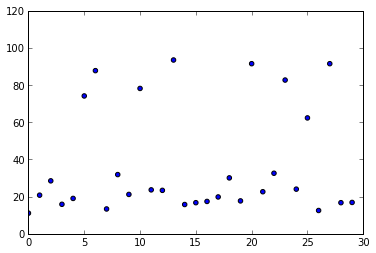
위의 차트는 1번 도로 하행선의 08:00의 4월 데이터이다. 살펴보면 대부분의 경우는 시속 20km 정도의 평균 시속을 보이지만 간혹 시속 80km에 가깝게 튀는 데이터들이 있다. 이는 주말에 차가 몰리지 않아서 생기는 현상이라고 결론짓고 넘어갈 수도 있지만 자세히 보면 그런 데이터의 절반은 평일에 일어난 데이터이다. 이를 토대로 다음과 같은 가설을 세울 수 있다.
하루하루 도로의 시간대별 평균 속도를 생성하는 분포는 두 개 있다.
즉, 평균적인 데이터를 생성하는 분포와 (1번 모델) 이상한 데이터를 생성하는 분포 (2번 모델) 두 개가 있다는 가정을 하는 것이다. 이제 데이터 생성 스토리를 만들어보자.[1]
For each road 1. Choose p ~ Uniform(0, 1) 2. Choose assignment ~ Bernoulli(p) 3. for each timepoint t: a. Choose μ[1](t), μ[2](t) ~ Uniform(0, 120) b. Choose σ[1](t), σ[2](t)~ Uniform(0, 100) c. μ(t) = μ[1](t) if assignment = 0 else μ[2](t) d. σ(t) = σ[1](t) if assignment = 0 else σ[2](t) e. Generate data d ~ Normal(μ(t), σ(t))
간단히 말해서, 임의의 확률로 두 모델 중 하나가 선택이 되고, 그에 맞는 정규 분포로부터 데이터가 생성된다는 이야기이다. 위의 생성 프로세스를 잘 살펴보면 기존의 접근 방법에서 취하던 각 시간별 데이터의 독립성이 사라졌음을 알 수 있다. 각 시간은 assignment에 의해 서로 연관이 되어 있다.
Posterior Distribution and Expected Loss Minimization
Prior distribution과 likelihood 계산을 위한 모델은 위의 데이터 생성 스토리에 모두 나타나 있다. 이제 이를 사용해서 μ(t)와 σ(t)의 posterior 분포를 계산해보는 것이 가능하다. Posterior distribution을 구하는 방법은 여러 가지가 있지만 나는 MCMC 기법을 활용하였다. 앞서 본 4월 데이터를 살펴보자.
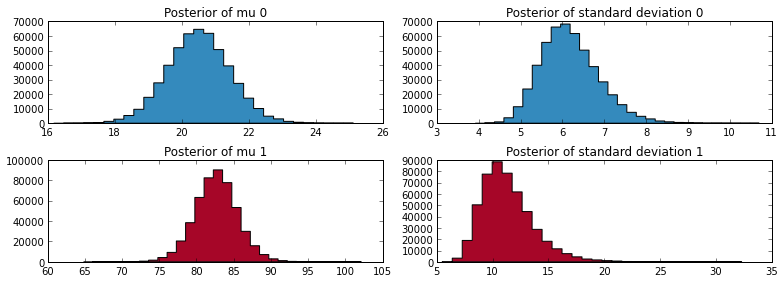
위의 posterior 분포를 보면 1번 모델은 대체로 20 정도의 μ를 중심으로 하고 있으며 2번 모델은 약 82 가량의 μ를 중심으로 하고 있음을 알 수 있다. 이는 위의 차트에서 확인할 수 있는 결과와 잘 맞아 떨어진다. 즉, 이를 통해 학습이 어느 정도 그럴싸하게 되었다는 것을 알 수 있다.
모델의 Posterior distribution을 얻어내면 이를 사용해서 데이터를 내가 원하는 만큼 생성할 수 있다. 이렇게 생성한 데이터가 진짜 분포로부터 생성된 데이터라고 가정하고 expected loss minimization을 행하면 된다. 기존 접근에서는 각 시간이 독립이므로 바로 중앙값을 취하면 그것이 최적해였지만 이제 한 번에 예측해야 하는 것이 벡터이므로 바로 중앙값을 계산하는 것은 불가능하다. 그러므로 임의의 해를 생성하여 그 해의 expected loss를 계산하고 이 해를 더 나은 해로 고치는 방식의 최적화를 통해서 expected loss를 minimize 한다. 이런 optimization을 위한 각종 최적화 라이브러리들이 많이 있으므로 이를 활용하면 된다.
Result
위의 예에서는 08:00의 데이터만 사용하였지만 위의 데이터 생성 스토리대로 각 도로의 24시간이 전부 연결되도록 한 번에 posterior를 생성할 수 있다. 하지만 예측해야 하는 변수가 도로별로 총 1,152개 (288개 시간 구간, μ, σ 각 두 개씩) 이므로 굉장히 많은 연산이 필요하다. 이를 쉽게 수행할 방법이 없어서 한 번에 두 시간 구간만 서로 연결이 되어 있다고 가정하고 학습을 하였다. 즉, 시간 t와 t+1이 공통의 p를 공유한다는 가정하에서 μ와 σ의 분포를 구해보았다.
학습 시간이 매우 오래 걸려서 MCMC의 iteration 회수를 많이 줄여서 학습시켰다. 이렇게 되면 통계적으로 안정적인 분포를 구할 수 없게 되므로 iteration 회수를 높이면 더 나은 결과를 얻을 수 있을 것이라는 기대를 할 수 있다. 시간적인 문제로 모든 도로에 대한 학습은 하지 못하고 몇 개의 도로만 뽑아서 결과를 비교해 보았다.
도로 1 하행선
중앙값 사용 12.38968749999999
새 모델 사용 12.438159722222231도로 10 하행선
중앙값 사용 2.760173611111111
새 모델 사용 2.9523258511926551
중앙값을 사용했을 때 전체 도로의 평균 loss가 4.7263이었음을 고려하면 도로 1은 예측과 크게 빗나간 예이고 도로 10은 예측과 아주 잘 맞아떨어진 예이다. 결과를 보면 여전히 중앙값을 사용한 모델이 더 좋지만 새 모델도 그에 근접하는 결과를 내는 것을 알 수 있다. 이 기법이 충분한 학습 시간을 할당 받지 못한 것을 고려하면 매우 고무적인 결과라 할 수 있다.
Model Averaging
중앙값을 사용했던 기존 결과보다 더 나은 결과를 내는 방법이 있다. 바로 모델 간의 평균을 사용하는 것이다. 즉, 중앙값을 사용한 모델과 위의 베이지안 접근 방법을 통해 얻은 모델의 결과를 평균 내는 것이다. 이 간단한 기법이 놀랍게도 더 나은 결과를 가져다준다.
도로 1 하행선
12.387465277777775도로 10 하행선
2.8562497311518831
아예 예측치가 매우 정확한 경우에는 (이미 예측이 충분히 좋으므로) 별 소득을 얻지 못했지만 그렇지 못했던 도로 1을 보면 두 모델보다 더 나은 결과를 얻어 내었다. 이는 bias-variance tradeoff[2] 때문이다. 서로 다른 두 모델을 평균 내면서 variance가 떨어져서 예측의 정확도가 높아지는 것이다.
Future Works
아직도 더 나은 예측을 위해 개선할 여지는 많이 남아 있다.
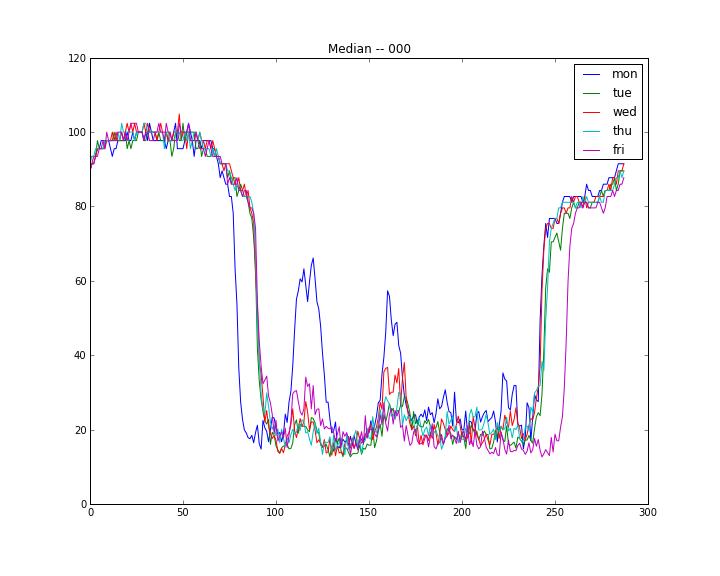
위의 차트를 보면 명백한데, 주중 데이터에도 도로마다 요일별 차이가 큰 경우가 많다. 우리가 예측하고자 했던 것은 화요일이니 화요일의 분포에서 크게 벗어나는 부분은 제거하는 것이 더 나은 결과를 내는데 도움이 될 것이다.
다른 한 가지 개선 방법은 더 나은 데이터 생성 프로세스를 생각해내는 것이다. 가령 위의 예에서는 정규 분포에서 데이터가 생성된다고 가정하였는데 이는 거짓말이다. 평균 시속은 절대 음수가 나올 수 없는데 위의 모델에 따르면 음수의 속도가 뽑힐 확률이 존재하기 때문이다. 더 그럴싸한 이야기를 만들 수 있으면 더 나은 결과를 얻을 수 있을 것이다. 그 밖에도 cross validation을 통해 어떤 데이터에 대해 좋지 않은 결과를 내는지 파악해보고 이를 해결할 수 있는 방법을 고민해보면 계속해서 예측을 개선해 나갈 수 있을 것이다.
Conclusion
Base model 보다 더 낫거나 최소한 그와 비슷한 결과를 내는 방법을 대회 참가 때에는 내놓지 못해서 아쉬움이 남았었는데 이번 분석을 통해서 그 아쉬움을 조금 달래보았다. 데이터 분석 및 base model과 MCMC를 활용한 모델의 소스 코드는 Github의 저장소에 공개해두었다.
[1]: 보통 plate notation을 많이 사용하지만 개인적으로는 모델의 이해에 큰 도움이 되지는 않는다고 생각한다. 이와 같은 의견은 여기에서 볼 수 있다.
[2]: Bias/Variance Tradeoff를 참고하기 바란다.