Introduction
SK planet에서 정기적으로 Code Sprint라는 프로그래밍 경진 대회를 주최한다. 얼마 전에 Code Sprint 2013의 라운드 2 결과가 나왔는데 운이 좋게도 내가 1위를 할 수 있었다. 이번 대회의 목표는 과거의 교통정보 데이터를 사용하여 미래의 교통정보를 예측하는 것이었다.
대회 페이지의 설명을 그대로 옮겨보면,
코드스프린트 Round2 문제에서는 2013년 4월부터 6월까지 3개월간의 T map 경부고속도로 교통정보를 제공하고 개발자는 이를 분석하여 7월 16일 24시간의 교통정보를 예측합니다.
자세한 내용은 공식 페이지를 방문하면 확인할 수 있다.
Exploratory Data Analysis
이런 식의 문제를 접하면 먼저 해야 하는 것이 몇 가지 있다. 가장 중요한 것 중 하나가 데이터를 살펴보는 것이다. 흔히 exploratory data analysis라고 하는데, 데이터를 살펴보고 이를 토대로 적절한 가설을 세우거나 앞으로의 진행 방향 등을 결정하기 위해서 반드시 필요한 작업이다.
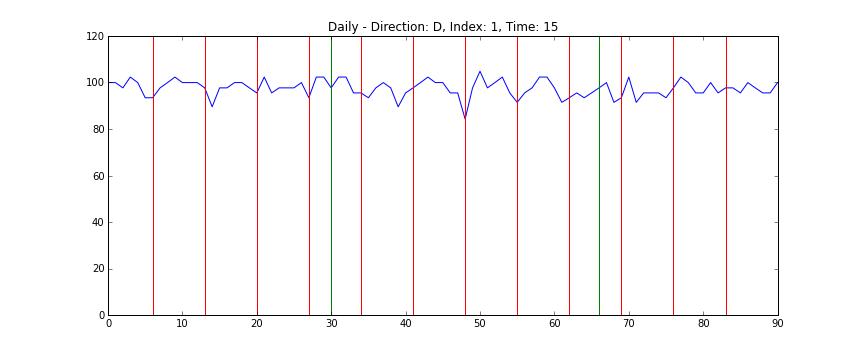
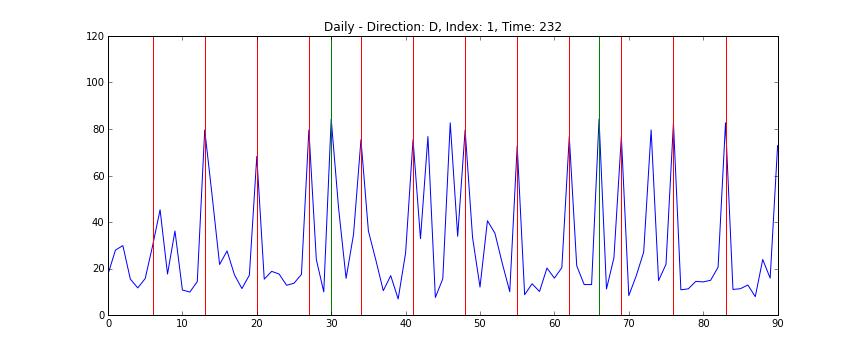
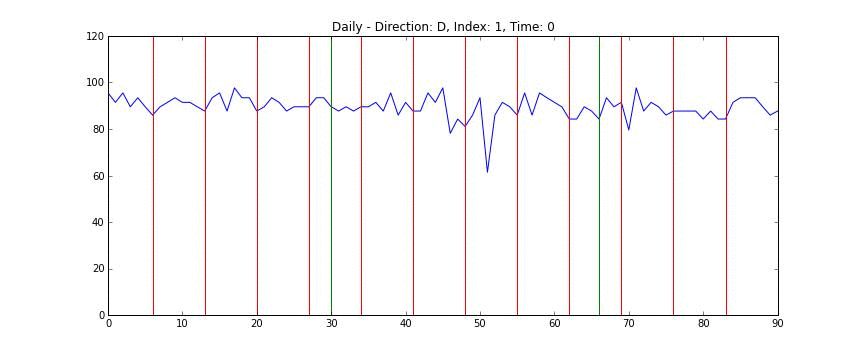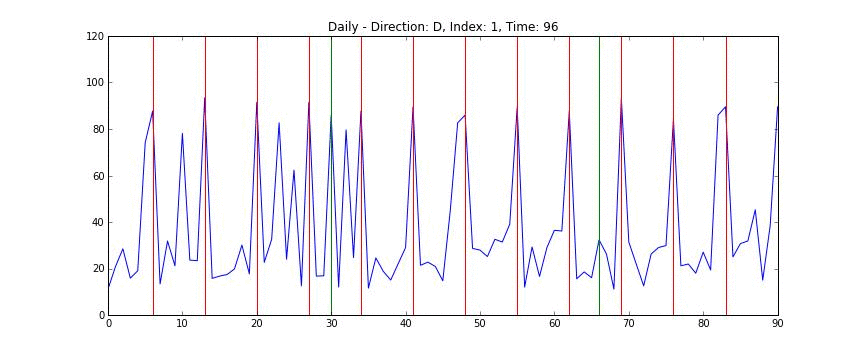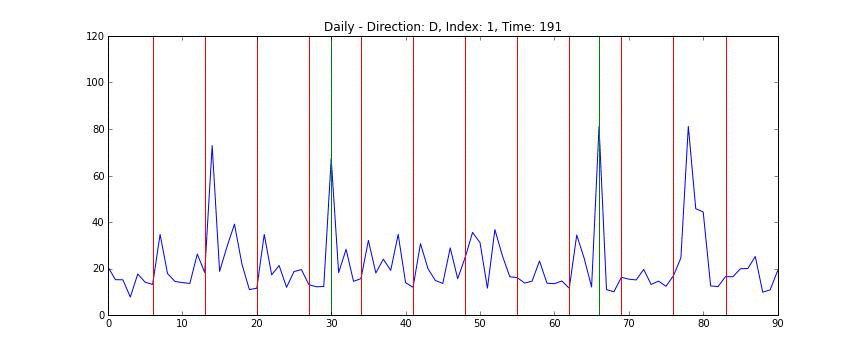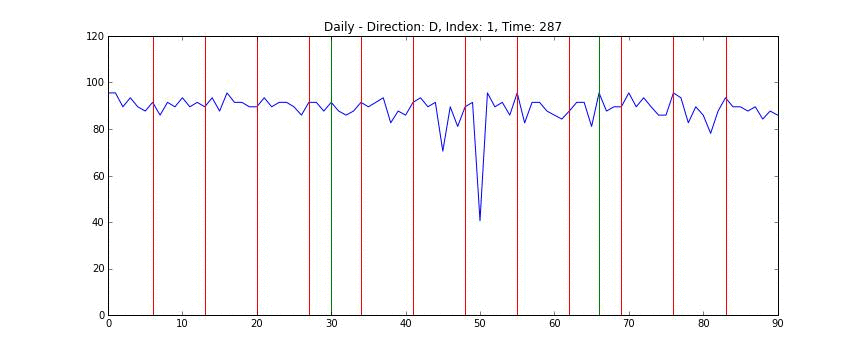
전체 데이터를 한 눈에 보는 것은 쉽지 않지만 개별 도로의 정보는 상대적으로 시각화하기 쉽다. 다음의 차트는 1번 도로의 일별 데이터를 시간축으로 자른 차트로, x축은 날짜를 (4월 1일부터 6월 30일까지) y축은 평균 시속을 (km/s) 의미한다. 빨간 선은 일요일을 의미하며 녹색 선은 공휴일이다 (현충일, 석가탄신일).
{kind=link}
위의 애니메이션을 보면 쉽게 알 수 있는데, 도로의 평균 속도는 매우 빠르다가 (약 100 km/h) 시간이 지나면서 매우 느려졌다가 (약 20 km/h) 다시 빨라지는 양태를 띄는 것을 알 수 있다. 또한 데이터를 가만히 살펴보면 주중과 주말의 양상이 많이 다른 것을 알 수 있다. 반면 주중의 움직임 끼리는 간혹 서로 다른 경우가 있지만 대체로 비슷한 것을 알 수 있다. 이를 토대로 다음과 같은 가설을 세울 수 있다.
주말의 데이터와 주중의 데이터를 따로 처리하는 편이 더 나은 예측을 하는데 도움을 줄 것이다.
더 데이터를 자세히 살펴보면 얻어 갈 수 있는 것이 많겠지만 대회에 참가할 때는 시간적 여유가 별로 없어서 이 정도만 살펴보고 바로 모델 생성에 들어갔다.
Statistical Model
많은 것들이 그러하듯 문제를 설명하는 모델을 만드는 작업도 매우 단순한 것을 만들어서 이를 baseline으로 삼고 조금씩 전진하는 것이 옳다. 가장 직관적으로 떠오르는 방법 중 하나가 과거의 데이터의 평균치 등을 미래의 예측치로 바로 사용하는 것이다. 매우 직관적이고 구현도 쉬운 방법이다. 실제 구현은 평균이 아니라 중앙값(median)을 사용하였는데, 이는 문제에서 주어진 loss function이 MAE (mean absolute error) 이었기 때문이다. 그리고 앞서 살펴보았듯, 전체 데이터를 사용하지 않고 주중의 데이터만 뽑아서 사용하였다. 놀랍게도 이번 대회의 우승 모델이 바로 이 방법이었다. 이러한 단순한 모델도 몇 가지 가정하에서 매우 그럴싸한 선택임을 보일 수 있다. 이를 설명하기 전에 문제를 Bayesian framework에서 접근해보자.
우리가 원하는 것은 하루하루 도로의 시간대별 평균 속도를 생성하는 분포를 모델링하는 것이다. 우리는 이 분포가 어떻게 생겼는지는 잘 모르지만 적어도 그 분포로부터 뽑아낸 샘플이 있다 (문제에서 주어진 데이터). 이는 Bayesian framework에서 보면 우리에게 posterior sample이 있는 셈이다. 이제 expected loss를 최소화하는 "답"을 우리의 예측치로 내놓으면 된다. 헌데 하나의 "답"이 추정해야 하는 변수가 72,576개나 된다 (상행/하행 * 126개 도로 * 288개 시간). 이상적이라면 이 모든 것을 한 번에 예측하는 것이 좋겠지만 상대적으로 많은 변수에 비해 우리가 가진 샘플의 개수는 고작 90여 개 (주중 데이터만 놓고 보면 60여 개) 밖에 되지 않는다 (4 ~ 6월 데이터). 이는 필연적으로 overfitting 문제로 귀결된다.
Overfitting 문제를 피하기 위해 모델을 단순화하는 가정을 추가해볼 수 있다. 가령 각 시간대별 데이터는 서로 독립이라고 가정해보자. 실제로는 앞 시간대의 교통 상황에 이후의 도로 상황이 큰 영향을 받겠지만 이를 무시하면 문제가 훨씬 접근하기 쉬워진다. 이제 우리는 동시에 72,576개의 변수를 추정해야 하는 것이 아니라 한 번에 한 개의 변수만 추정하면 되고 이를 72,576회 반복하면 되는 것이다. 그런데 이렇게 놓고 보니 주어진 posterior sample에 대한 expected loss를 최소화하는 답은 각 시간대별 중앙값이 되어버린다. 결국 시간대별 데이터의 독립을 가정하면 중앙값을 취하는 것이 최적의 선택이라는 결론을 얻을 수 있다.
Thoughts
실제 대회에 참가할 때 위의 모델을 만드는 것은 얼마 걸리지 않았다. 그리고 이를 더 개선하는 방법을 고민해보았는데 뾰족한 수가 별로 없었다. 일단 가장 큰 문제는 예측을 해야 하는 날이 주어진 데이터로부터 보름가량 이후의 일이라는 것이었다. 상식적으로 생각해봐도 보름 전의 도로 상황이 보름 후의 도로 상황에 영향을 줄 것이라고 생각하기 힘들다. 결국 평범한 regression 문제로 접근하는 것은 잘못된 방법이라고 판단을 내렸다. 결국 더 나은 예측을 위해서는 baseline 모델에서 가정한 것을 더 완화해야 했는데 이는 쉽지 않았다. 가장 큰 문제는 데이터의 부족이었다. 예측해야 하는 변수를 2개로 한정 짓고 Gibbs sampling을 해보려고 하였으나 간단한 테스트 결과 overfitting 문제에 빠지기 십상임이 판별되었다. 지금 와서 드는 생각이지만 데이터를 더 면밀하게 살펴보는 쪽으로 일찌감치 생각을 돌리고 더 현실적인 posterior sample을 골라내는 방법을 생각해봤어야 했다. 아쉽게도 실제 대회에서는 그쪽으로 생각이 미치기 전에 대회가 마감되었다.
대회에 세 개의 예측치를 제출할 수 있었는데 고민하다가 Gradient boosting regression을 활용한 방법을 두 개 추가로 제출하였다. Regression이 개념적으로는 틀린 접근 방법이라고 생각했지만 지푸라기 잡는 심정의 접근이었다고 고백한다. 마감 시간이 얼마 남지 않아서 패러미터 튜닝조차 제대로 하지 못하고 제출하였기에 예상대로 결과는 중앙값을 사용한 모델의 결과에 미치지 못하였다.
대회 자체에 대한 몇 가지 아쉬움이 있다. 많은 사람들이 생각했겠지만 단 하루의 데이터를 예측하는 것은 결코 통계적인 안정성을 보장할 수 없다. 내가 1위를 하게 된 것도 많은 부분 운이 따라줬기 때문이라고 생각한다. 그리고 과거 데이터도 더 많이 제공했더라면 좋지 않았을까 하는 아쉬움도 남는다. 실제로 어떻게 될지는 모르겠지만 이렇게 했더라면 overfitting 문제가 약간은 해결되지 않았을까 기대하기 때문이다. 또한 보름 후의 데이터 예측이라는 측면도 논란의 여지가 있다고 여기는 사람들이 꽤 있을 것으로 생각한다. 그리고 마지막으로 서로의 결과를 비교해 볼 수 있는 과정이 있었으면 좋았을 것 같다. 내가 얼마나 잘 했는지 전혀 평가가 되지 않는 상황이라 많은 사람들이 흥미를 금방 잃었을 것으로 생각한다.
어찌 되었든 참가를 마음먹고 문제에 대해 고민한 3, 4일간 매우 즐거웠다. Baseline model보다 더 나은 것을 만들어보려고 고민하는 과정은 고통스럽지만 즐거운 경험이다. 이런 멋진 대회를 준비하고 진행한 SK planet 에게 감사를 표한다. 아마 다음 포스팅은 정답 세트를 놓고 기존에 사용한 접근 방법 및 새로운 방법들의 비교를 하는 일종의 postmortem이 되지 않을까 생각한다.